Compute Lack-of-Fit and Pure Error Anova Table for a Linear Model
anovaPE.RdCompute a lack-of-fit and pure error anova table for either a linear model with one predictor variable or else a linear model for which all predictor variables in the model are functions of a single variable (for example, x, x^2, etc.). There must be replicate observations for at least one value of the predictor variable(s).
anovaPE(object)Arguments
- object
an object of
class"lm". The object must have only one predictor variable in the formula, or else all predictor variables in the model must be functions of a single variable (for example, x, x^2, etc.). Also, the predictor variable(s) must have replicate observations for at least one value of the predictor variable(s).
Finally, the total number of observations must be such that the degrees of freedom associated with the residual sums of squares is greater than the number of observations minus the number of unique observations.
Details
Produces an anova table with the the sums of squares partitioned by “Lack of Fit”
and “Pure Error”. See Draper and Smith (1998, pp.47-53) for details.
This function is called by the function calibrate.
Value
An object of class "anova" inheriting from class
"data.frame".
References
Draper, N., and H. Smith. (1998). Applied Regression Analysis. Third Edition. John Wiley and Sons, New York, pp.47-53.
Millard, S.P., and Neerchal, N.K. (2001). Environmental Statistics with S-PLUS. CRC Press, Boca Raton, Florida.
Examples
# The data frame EPA.97.cadmium.111.df contains calibration data for
# cadmium at mass 111 (ng/L) that appeared in Gibbons et al. (1997b)
# and were provided to them by the U.S. EPA.
#
# First, display a plot of these data along with the fitted calibration line
# and 99% non-simultaneous prediction limits. See
# Millard and Neerchal (2001, pp.566-569) for more details on this
# example.
EPA.97.cadmium.111.df
#> Cadmium Spike
#> 1 0.88 0
#> 2 1.57 0
#> 3 0.70 0
#> 4 0.80 0
#> 5 0.54 0
#> 6 1.83 0
#> 7 1.34 0
#> 8 10.17 10
#> 9 11.13 10
#> 10 11.66 10
#> 11 10.80 10
#> 12 11.11 10
#> 13 11.95 10
#> 14 11.14 10
#> 15 19.97 20
#> 16 20.28 20
#> 17 23.20 20
#> 18 22.12 20
#> 19 18.01 20
#> 20 24.83 20
#> 21 21.10 20
#> 22 54.78 50
#> 23 49.00 50
#> 24 51.92 50
#> 25 49.00 50
#> 26 54.75 50
#> 27 50.25 50
#> 28 50.03 50
#> 29 97.06 100
#> 30 94.60 100
#> 31 102.54 100
#> 32 101.09 100
#> 33 99.20 100
#> 34 93.71 100
#> 35 100.43 100
# Cadmium Spike
#1 0.88 0
#2 1.57 0
#3 0.70 0
#...
#33 99.20 100
#34 93.71 100
#35 100.43 100
Cadmium <- EPA.97.cadmium.111.df$Cadmium
Spike <- EPA.97.cadmium.111.df$Spike
calibrate.list <- calibrate(Cadmium ~ Spike,
data = EPA.97.cadmium.111.df)
newdata <- data.frame(Spike = seq(min(Spike), max(Spike), length.out = 100))
pred.list <- predict(calibrate.list, newdata = newdata, se.fit = TRUE)
pointwise.list <- pointwise(pred.list, coverage = 0.99, individual = TRUE)
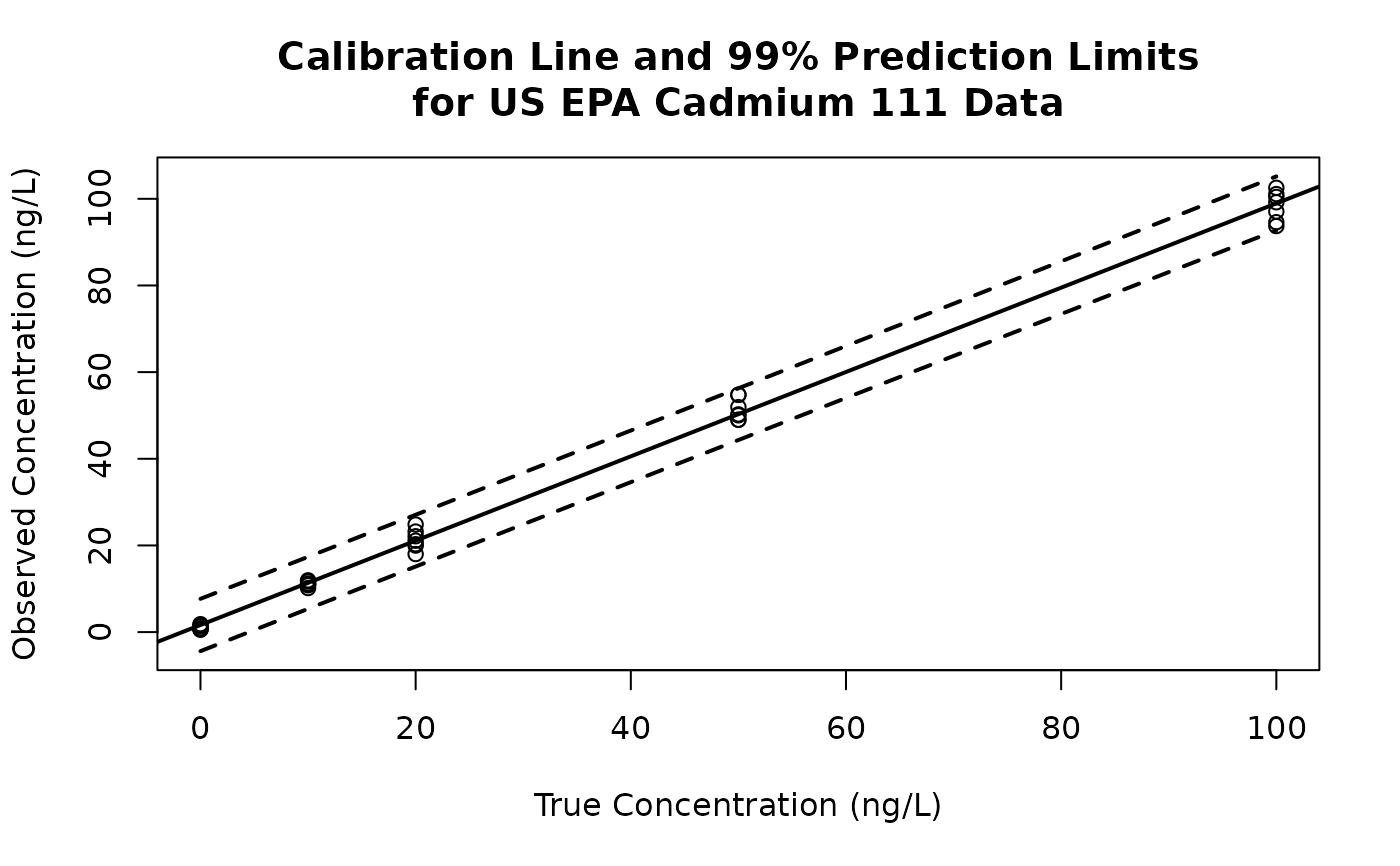
plot(Spike, Cadmium, ylim = c(min(pointwise.list$lower),
max(pointwise.list$upper)), xlab = "True Concentration (ng/L)",
ylab = "Observed Concentration (ng/L)")
abline(calibrate.list, lwd = 2)
lines(newdata$Spike, pointwise.list$lower, lty = 8, lwd = 2)
lines(newdata$Spike, pointwise.list$upper, lty = 8, lwd = 2)
title(paste("Calibration Line and 99% Prediction Limits",
"for US EPA Cadmium 111 Data", sep="\n"))
 rm(Cadmium, Spike, newdata, calibrate.list, pred.list,
pointwise.list)
#----------
# Now fit the linear model and produce the anova table to check for
# lack of fit. There is no evidence for lack of fit (p = 0.41).
fit <- lm(Cadmium ~ Spike, data = EPA.97.cadmium.111.df)
anova(fit)
#> Analysis of Variance Table
#>
#> Response: Cadmium
#> Df Sum Sq Mean Sq F value Pr(>F)
#> Spike 1 43220 43220 9356.9 < 2.2e-16 ***
#> Residuals 33 152 5
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#Analysis of Variance Table
#
#Response: Cadmium
# Df Sum Sq Mean Sq F value Pr(>F)
#Spike 1 43220 43220 9356.9 < 2.2e-16 ***
#Residuals 33 152 5
#---
#Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#Analysis of Variance Table
#
#Response: Cadmium
#
#Terms added sequentially (first to last)
# Df Sum of Sq Mean Sq F Value Pr(F)
# Spike 1 43220.27 43220.27 9356.879 0
#Residuals 33 152.43 4.62
anovaPE(fit)
#> Df Sum Sq Mean Sq F value Pr(>F)
#> Spike 1 43220 43220 9341.559 <2e-16 ***
#> Lack of Fit 3 14 5 0.982 0.4144
#> Pure Error 30 139 5
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
# Df Sum Sq Mean Sq F value Pr(>F)
#Spike 1 43220 43220 9341.559 <2e-16 ***
#Lack of Fit 3 14 5 0.982 0.4144
#Pure Error 30 139 5
#---
#Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
rm(fit)
rm(Cadmium, Spike, newdata, calibrate.list, pred.list,
pointwise.list)
#----------
# Now fit the linear model and produce the anova table to check for
# lack of fit. There is no evidence for lack of fit (p = 0.41).
fit <- lm(Cadmium ~ Spike, data = EPA.97.cadmium.111.df)
anova(fit)
#> Analysis of Variance Table
#>
#> Response: Cadmium
#> Df Sum Sq Mean Sq F value Pr(>F)
#> Spike 1 43220 43220 9356.9 < 2.2e-16 ***
#> Residuals 33 152 5
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#Analysis of Variance Table
#
#Response: Cadmium
# Df Sum Sq Mean Sq F value Pr(>F)
#Spike 1 43220 43220 9356.9 < 2.2e-16 ***
#Residuals 33 152 5
#---
#Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#Analysis of Variance Table
#
#Response: Cadmium
#
#Terms added sequentially (first to last)
# Df Sum of Sq Mean Sq F Value Pr(F)
# Spike 1 43220.27 43220.27 9356.879 0
#Residuals 33 152.43 4.62
anovaPE(fit)
#> Df Sum Sq Mean Sq F value Pr(>F)
#> Spike 1 43220 43220 9341.559 <2e-16 ***
#> Lack of Fit 3 14 5 0.982 0.4144
#> Pure Error 30 139 5
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
# Df Sum Sq Mean Sq F value Pr(>F)
#Spike 1 43220 43220 9341.559 <2e-16 ***
#Lack of Fit 3 14 5 0.982 0.4144
#Pure Error 30 139 5
#---
#Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
rm(fit)